Continuing on from my post about Optimal Layout I also tried out Divvy (version 1.2.3) for more efficient window management on Mac OS X. My work setup is a MacBook Pro with an external display and Spaces enabled. An important goal is to achieve keyboard only window control.
Divvy is a very simple app. It essentially enables you to divide the screen up into a virtual grid and snap the current window to a region within that grid. The other major feature is the ability to assign keyboard shortcuts to particular regions, enabling you to position and size the current window to one of your predefined regions with ease. There is also an option to use the keyboard shortcuts to move the current window to another display, which I find quite useful.
To tile all the windows on the screen in a particular layout requires shifting the focus to each window to position and size it. If your Divvy shortcuts correspond to where you want the windows than this whole process can be done fairly quickly, without touching the mouse/trackpad. Having said that, I would love to define a layout on the Divvy grid and with a keyboard shortcut arrange all windows on the current screen into that layout.
I have Windows XP running in a Parallels VM in Coherence mode and Divvy does not seem to work with the Windows windows. Some applications (such as Activity Monitor) also have restrictions on window size that Divvy can't change.
Over the days I was trialling Divvy on my work MacBook Pro, I found myself missing it on the Mac at home. For USD$14 and a license that supports use on multiple Mac's, it is good value.
Wednesday, November 24, 2010
Divvy
Tuesday, November 23, 2010
Optimal Layout
Inspired by xmonad on linux, I tried out Optimal Layout (version 1.1.2) for more efficient window management on Mac OS X. My work setup is a MacBook Pro with an external display and Spaces enabled. An important goal is to achieve keyboard only window control.
In Optimal Layout, tiling windows in an arrangement requires
- explicitly selecting the windows in the Optimal Layout UI
- selecting a layout from a list
- selecting the target display
My most common use case is to arrange windows in the current space on the display with the focus, i.e. my current context. There are too many steps for this to feel efficient.
The available window layouts are predefined, including the window sizing. After arranging windows, sizing adjustments can be made using the sticky resizing feature, but this requires using the mouse. Furthermore, should you open one more window, you have to go through the whole process again.
I am disapointed with Optimal Layout and am trying out Divvy, which I will post about next.
Thursday, October 28, 2010
Installing XMonad on Ubuntu 10.10 Maverick Meerkat
I installed Ubuntu 10.10 Maverick Meerkat (in Parallels on my Mac) to try out XMonad, the tiling window manager. XMonad is a candidate if I move off the Mac. I am slowly increasing my keyboard use and relying less on the mouse and XMonad is a further step in that direction.
I have never installed or used Xmonad before and after too much time stuffing around with the usual linux problems, these are the steps I followed to get a simple, initial installation working on a fresh install of Ubuntu.
- Install Haskell, XMonad and dmenu.
$ sudo apt-get install haskell-platform xmonad dwm-tools
Originally, I installed Haskell and then tried to install XMonad via Cabal. Unfortunately the xmonad-contrib package failed to install due to dependency issues. - Set XMonad to be the window manager for Gnome.
$ gconftool-2 -s /desktop/gnome/session/required_components/windowmanager xmonad --type string
Found this at Xmonad/Using xmonad in Gnome. Don't log out or restart X now. If you do, you will find XMonad workspace 1 broken. It seems to consist of two Gnome panels tiled to fill the screen but hidden behind the desktop and any further windows you create are also hidden. The next step fixes this. - Create a simple Xmonad configuration file.
$ mkdir ~/.xmonad
$ touch ~/.xmonad/xmonad.hs
Set the contents ofxmonad.hstoimport XMonad
import XMonad.Hooks.ManageDocks
main = xmonad $ defaultConfig {
manageHook = manageDocks <+> manageHook defaultConfig,
layoutHook = avoidStruts $ layoutHook defaultConfig
}
Apply the configuration.$ xmonad --recompile
This configuration was found at Xmonad/Config archive/John Goerzen's Configuration. - Logout and back in again. You should see a standard looking Ubuntu desktop with the menubar across the top and the normal panel along the bottom. See the tour to get started with the XMonad commands.
Tuesday, October 19, 2010
Defamation?
Yesterday I received a letter from lawyers representing a doctor named in my post Tony's letter to the Medical Board of Queensland. They claim the letter contains defamatory statements and demanded I remove the post.
At the time I posted this blog entry, Tony was missing and left a public message of possible self harm. People were looking for him, his family was worried and many people in the programming communities Tony frequented online feared for his safety. I published Tony's letter at that time for those people online that had seen and were discussing his message, but had no awareness of the real situation.
I do not wish to remove the blog post as it captures a small part of the prolonged trauma Tony endured in engaging with the medical system. I have no reason to doubt that all the practitioners Tony saw genuinely believed they were doing the right thing. This does not change the experience of the patient though. It can be a demoralising cycle of slowly progressing from generalists to specialists, booking appointments weeks/months into the future meanwhile enduring symptoms, bearing the financial burden, deciphering sometimes poor communication, having to evaluate practitioners and their advice and decide next steps in the face of enduring pain.
I am disappointed that one of the doctor's involved has resorted to this level of legal involvement against me. Instead of attempting to censor, he could have simply written a rebuttal. I defy anyone that claims the medical system (as a whole) handled Tony's case well. Therefore there is room for improvement that is better served by reflection and constructive criticism rather than a legal approach.
I am not a lawyer and have no experience with defamation law. I have removed the doctor's name from the blot post in an attempt to avoid legal confrontation.
Monday, October 4, 2010
Why are helmets mandatory for cycling?
The issue of mandatory helmet laws for cycling has been growing in public awareness. This is possibly due to recent court cases and research, the proported lack of take up of the Melbourne Bike Share and the brand new Brisbane CityCycle program.
Proponents of repealing mandatory helmet laws generally focus their discussion on practical issues. They cite the lack of compelling scientific research regarding helmet efficacy in preventing serious brain injury, the deteriorating overall physical health of society and improving sustainability through lower impact on the environment. My question is should they be required to do that?
Supposedly Australia is a free, civilised country. We value our individual freedom. This freedom includes daily choices concerning how our own actions affect our own good, balancing our own personal risk against convenience, benefit and enjoyment. We make these choices whenever we drive our cars, fly in an aeroplane, jump out of an aeroplane, take up smoking, drink varying volumes of alcohol and go swimming.
By definition mandatory helmet laws restrict individual freedom. The cyclist is unable to make the choice of balancing personal risk against convenience, benefit and enjoyment. It does not matter what type of bike is being ridden, the speeds, riding surface, distance travelled and presence or absence of vehicles.
So my question is why isn't the government required to justify the presence of mandatory helmet laws, since they are exercising power over individual freedom, against some people's will? Such a justification would necessarily be in terms of preventing harm to others, otherwise it impinges on the individual freedom we as a society also claim to value. If no such reasonable justification is available then repealing the laws is the sensible and rational course of action to take.
Sunday, September 19, 2010
QOTD
I consider it extremely important–perhaps vital, even–to spend time engaging others intelligently who have diverging views from one’s own. I think that this is, on the whole, one of the most valuable uses of one’s time that exists. Whether it’s consulting a disagreeable book or a person, somehow at the intersection of intelligence and difference lies a “something” that is mind-expanding.
From Sealed Abstract - Why I stopped reading HN via @conal
Thursday, September 16, 2010
Single exponential smoothing and foldl
Recently I looked at simple techniques for time series smoothing and forecasting. One such primitive method is the single exponentially weighted moving average (SEWMA), defined as
where the sequences are indexed from 1.  denotes an observed value of the time series and
denotes an observed value of the time series and 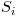 a SEWMA value. In words, this recursive definition expresses that the next SEWMA value is a weighted average of the curent observed and SEWMA values.
a SEWMA value. In words, this recursive definition expresses that the next SEWMA value is a weighted average of the curent observed and SEWMA values.
If I pose the question "What is the predicted value for the next time series observation?" we just apply the formula.
A typical imperative implementation
sewma <- function (alp, y) {
S <- y[1]
for (t in 2:length(y)) { S <- alp * y[t] + (1-alp) * S }
S
}This is R code, but it should look familiar enough to anyone who has written Java, C#, etc.Haskell implementation
In Haskell, a fold is a way of recursively iterating a data structure, accumulating a return value. The left fold has type
foldl :: (a -> b -> a) -> a -> [b] -> aDenote one of the values from the conceptual sequence of accumulator values as
foldl f s y = ...
. The function f maps from the current accumulator and list values to the next accumulator value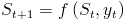
which is the form of the SEWMA equation above. The
foldl1 function is a specialisation of foldl that uses the first value of the list as the initial accumulator value, yielding the implementationsewma alp = foldl1 (\s y -> alp * y + (1-alp) * s)
Revisiting R
R has the
Reduce function for performing folds. sewma <- function (alp, ys) {
Reduce(function (S, y) { S <- alp * y + (1-alp) * S }, ys[2:length(ys)], ys[1])
}Summary
If accumulating a value over a data structure can be represented with a step function of the form
then a left fold captures the recursive implementation.
Monday, September 6, 2010
Haskell mode in MacVim
I set up Haskell mode (haskellmode-20100622.vba) in MacVim 7.3 (53). As a Vim newbie I found this page useful, even though it says pretty much the same thing as the Haskell mode project page.
I followed the instructions and created $HOME/.vimrc with these contents.
" use ghc functionality for haskell filesUnfortunately when I edited a Haskell file none of the Haddock integration was working. I assume the
au Bufenter *.hs compiler ghc
" switch on syntax highlighting
set syntax on
" enable filetype detection, plus loading of filetype plugins
set filetype plugin on
" Configure browser for haskell_doc.vim
let g:haddock_browser = "open"
let g:haddock_browser_callformat = "%s %s"
haskell_doc.vim filetype plugin wasn't being loaded because the :DocSettings command failed with E492: Not an editor command.After some hours I changed the line
set filetype plugin on to :filetype plugin on and Haddock integration now works (don't know why). I am using the Haskell Platform which includes the documentation.After reading A minimal Vim configuration I have switched from
$HOME/.vimrc to $HOME/.gvimrc with these contents." line numbers
set number
" show the cursor line and column number
set ruler
" turn off blinking cursor in normal mode
set gcr=n:blinkon0
" hide the toolbar
set go-=T
" switch on syntax highlighting
set syntax
" highlight matches in a search (hls)
" show the current matching pattern as you search (is),
" ignore case (ic) unless you are searching for both upper and lowercase letters (scs)
set hls is ic scs
" use ghc functionality for haskell files
au Bufenter *.hs compiler ghc
" enable filetype detection, plus loading of filetype plugins
:filetype plugin indent on
" Configure browser for haskell_doc.vim
let g:haddock_browser = "open"
let g:haddock_browser_callformat = "%s %s"
Wednesday, July 28, 2010

Monday, July 12, 2010
Charles Leadbeater: Education innovation in the slums (TED talk)
- education that works by pull not push
- learning has to be productive to make sense
- learning that starts from questions not from knowledge in curriculum
- Chinese restaurant model instead of McDonalds model
- technology that makes learning fun and accessible
In these models, it seems the "teacher" plays more of a mentor type role of guiding and encouraging.
Wednesday, July 7, 2010
Managing PDF books and papers
I have a small collection of mathematical and computer science books and papers as PDF files. Some are stashed in Google Docs, others in Read it Later and others as links in email, etc. It would be nice if:
- all documents were organised together
- I could access the documents from all my devices - work and home macs and iPad
- adding / removing documents automatically synchronised across all devices
- there is a record of the url each document came from
- document contents are searchable
A cloud solution with device specific apps would be a good start. I would be happy to pay an annual price similar to flickr and Remember the Milk for a good product. From memory these are about USD$25 / year.
All the solutions I have come across are intended for academic bibliographic management. Most of my documents were collected adhoc from the web, without access to restricted channels such as the ACM Digital Library. The tools are geared towards searching the popular open and paid publication repositories and extracting bibliographic details automatically. I can see how this would be very useful if you have access, but I found it problematic in matching my documents when I don't have access. Given my requirements this became more hassle then it was worth.
Some solutions integrate social networking. Being able to share your reading and observe what others are reading might be quite useful. Warrants future investigation.
I don't have any need to annotate, highlight or add notes to the PDF files at present.
Papers
A Mac application (USD$42) featuring document synchronisation with the corresponding iPhone and iPad apps (USD$17.99). Storing the database and documents on Dropbox should also enable sharing between Macs. Metadata and content are searchable and the full screen reading mode is great. You can add notes to documents, but not annotate or highlight portions. At work I am behind a strict corporate firewall and proxy. Papers gave a spurious error about internet connectivity and disabled all online actions. Following this forum post fixed things up.
I had high hopes for Papers. The iPad synchronisation is very compelling, but otherwise it currently doesn't do enough for me to warrant paying money for (and putting my data in) Mac only software. If I end up regularly using the supported repositories then I will probably reconsider.
Mendeley
A web application with a companion Mac/Windows/Linux desktop app. There is no iPad app, although it is apparently in the works. The desktop UI looks like it is Java and is a bit clunky on the Mac.
The desktop app is orientated around managing your documents and associated files. You can add your files, set their metadata and sync with your website account. Synchronisation is initiated manually via a UI button. There is a full screen viewer, although I couldn't figure out the zoom and navigation keys. Alternatively you can open documents with the default external application. Document annotations, highlighting and notes are all supported, as well as full text searching. Unfortunately the network proxy settings aren't automatically detected from System Preferences and I need to manually edit them when taking the MacBook Pro between work and home.
On the website you can manage your references and notes and view your files, but I couldn't figure out how to upload files or see annotations and highlighting. Otherwise, the web site is all about social networking. You get 500MB of personal storage space and 500MB of shared space. The first upgrade is USD$4.99/month for 3.5GB + 3.5GB.
To make it attractive for me, Mendeley needs to tidy up the desktop app, automatically sync in the background, make the full screen view useful, release a synchronised iPad app and lower the price.
BibDesk + Dropbox + Skim + GoodReader
BibDesk is a Mac BibTex editor and reference manager. I can record as much metadata as is convenient, associate url's and PDF files, organise and search. By storing the BibDesk database file and PDF files on Dropbox, both content and metadata is automatically synchronised between all Macs. Dropbox provides 2GB of free storage, which is a great to get started. Skim is a PDF reader with a decent full screen mode on the Mac. GoodReader (USD$1.19) is a PDF viewer with Dropbox integration on the iPad. Although it is much quicker to transfer documents to GoodReader via iTunes.
The main downside with this setup is the lack of BibDesk support on the iPad and that all documents aren't automatically synchronised locally to the iPad. It is sufficient for me now though, as I am currently only adding new documents periodically.
CiteULike
Web site sponsored by Springer. I haven't investigated it properly, but it looks like you can add references from the major publication repositories or add your own, upload the associated documents and setup social connections. There are no Mac or iPad apps, so you need to manage your local files and how to view them yourself.
Friday, July 2, 2010
QOTD
Do not have the mind set that the day you release version 1.0 is the finish line, it’s the starting line, so hurry up and get there.
-- Sam Howley
From: Lessons learned from 13 failed software products via @ericries
Tuesday, June 29, 2010
QOTD
It's not that people cannot think mathematically. It's that they have enormous trouble doing it in a de-contextualized, abstract setting.
-- Keith Devlin
From In Math You Have to Remember, In Other Subjects You Can Think About It
Tuesday, June 22, 2010
Masters to Graduate Diploma
In 2008 I commenced a coursework Masters in mathematics at the University of Queensland. I have downgraded this to a Graduate Diploma and should officially graduate in a few weeks.
My original goal for commencing postgraduate study was to improve my knowledge in programming languages and make the current research more accessible. Unfortunately the local universities teach very little (relevant) theoretical computing science, so I enrolled in mathematics with a focus on discrete mathematics, logic and abstract algebra. After the first year I discovered that there is no real future in programming language research here in Brisbane. I had achieved my goal in the context of the courses available and so switched my study to statistics as data analytics is both interesting and hopefully more viable locally.
To complete the Masters I need to do the equivalent of four courses in research. As I am enrolled in a coursework masters, I pay 2-3 times the standard undergraduate fees. The last course cost $2010. Therefore there is approximately $8000 in fees remaining.
I would enjoy the remaining Masters research component if could find the right supervisor and topic. However employment as a researcher now generally requires a PhD, not a Masters and while a PhD is longer, it also has no fees. So if the circumstances were right to do the Masters research it makes more sense to consider a PhD anyway.
The value proposition for completing the Masters is too low. I have fulfilled the requirements for a Graduate Diploma and so will finish with that.
Tuesday, May 25, 2010
Education is not linear
And we have sold ourselves into a fast food model of education and it's impoverishing our spirits and our energies as much as fast food is depleting our physical bodies.
-- Ken Robinson
Tuesday, May 11, 2010
Brief summary of iPhone Flickr apps
I use Flickr to store my photos. Now that I have an iPhone, I would like to use it as a mobile photo album as well as uploading photos taken from the camera. I don't want the added complexity of using iPhoto as a middleman, so I did a rough survey of iPhone Flickr apps.
Flickr 1.1.3 (free).
- Loads photos fast. Caching works well if you have already viewed a photo.
- View photos full screen and swipe to navigate.
- No zoom.
- If you take photos with the inbuilt Camera app and upload them sometime later, it doesn't set the map location and time taken to the original values.
- Uploaded photo file size seems larger than with Mobile Fotos or syncing with iPhoto.
Darkslide 1.6.2 (free add-supported version)
- Slow load times (even for previously viewed photos).
- No swipe to nagivate photos.
- No zoom.
Flickit 2.0 (free)
- Only does uploading. The Pro app ($5.99) is a full client.
- If you take photos with the inbuilt camera app and upload them sometime later, it doesn't set the map location and time taken to original values. Found an explanation from the developer.
- Compresses photos significantly. I could only see small differences compared with the same photo uploaded via alternative means. Developer was helpful when I asked about this.
Mobile Fotos ($5.99)
- Upload correctly sets the map location and time taken to the original values for photos taken with the inbuilt Camera app.
- View photos full screen, swipe to navigate and pinch to zoom.
- Slideshow.
- Uploaded photos have washed out colours.
- Can't select from your tags when uploading, need to type in each time.
- Had one case where photos were shown as a blank screen. Cleared cache and problem was resolved.
- Developer was responsive when I asked questions.
Reflections ($5.99) and Photo Wallet: Flickr ($3.99) both look interesting in their own right, but neither offer zoom. The developer of Photo Wallet answered my question via twitter quickly to.
In summary, none of the Apps I tried are ideal for uploading to Flickr. This leaves me importing into iPhoto and uploading via the standard web uploader.* Mobile Fotos has the best viewing experience and I would also use it for uploading if the colours and tagging were fixed.
* The iPhone saves GPS information into the EXIF data. I had to set the "Import EXIF location data" privacy setting for the Flickr map location to be set. The privacy implications of this need further investigation.
Tuesday, April 13, 2010
Sunday, March 21, 2010
Embedding LaTeX in Blogger take 2
After further consideration on Embedding LaTeX in Blogger I have the following concerns in using jsLaTeX.
- LaTeX images not rendered in RSS readers
- Stability of all the components over (a long) time
jsMath improves on point 2, but looks way too hard to host on Blogger. So I am falling back to using images generated by the CodeCogs online equation editor hosted on Picasa, which is where Blogger uploads images. I put the LaTeX source in the
img alt attribute.Blogger resizing images
After adding a few equations through the standard Blogger mechanism, I noticed that they weren't as clear when previewing. The following two equations are the same image hosted on Picasa, but embedded with different src urls.
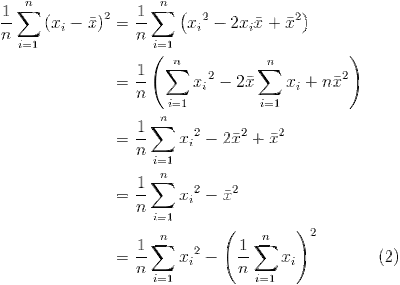
This is using the Blogger generated url in the image tag and has size 400 x 285 pixels.
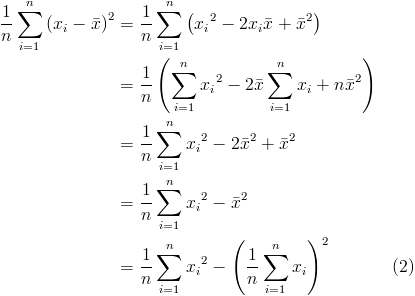
This is using the Picasa generated url and has the original size of 415 x 296 pixels.
Notice how the first image is both smaller and blurry. It seems that Blogger is automatically resizing it. Unfortunately this means a little more work for each equation as it requires generating the link in Picasa and replacing the Blogger generated image tag.
Computing variance
Given a list of n numbers 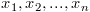 , the variance is defined as
, the variance is defined as
where  is the arithmetic mean.
is the arithmetic mean.
Expression 1 stated in words is the average squared difference of each data point from the mean. Implemented as an algorithm, this requires two passes over the data set. The first to calculate the mean and the second to sum the squared differences.
Let's derive the more commonly used expression for variance.
This only requires a single pass over the data set, computing the incremental sum of the values and the incremental sum of their squares. However, if the terms in the subtraction are large and close enough, catastrophic cancellation can occur. Essentially the precision of the floating point representation is exceeded, yielding unacceptable results. See Algorithms for calculating variance and Theoretical explanation for numerical results for examples (they are calculating the sample variance which is slightly different). More detailed information on catastrophic cancellation can be found in What Every Computer Scientist Should Know About Floating Point Arithmetic (1991).
A more numerically stable (but computationally expensive) single pass algorithm was published by Knuth in The Art of Computer Programming, volume 2. Define 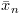 and
and  as the mean and sum of squared differences of the the first n values respectively.
as the mean and sum of squared differences of the the first n values respectively.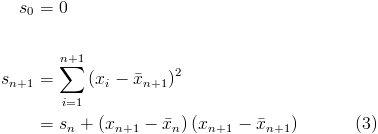
For m > 0 values, the variance is then  .
.
Derivation of Equation 3
This is really just a more verbose version of one-pass algorithm to compute sample variance. First up is the running mean.
If you think of the mean visually i.e. a horizontal line through the data on a scatter plot, then it is intuitive that the sum of the distances between each point and the mean is zero.
Now define  as the difference of consecutive incremental means, along with a few useful variations.
as the difference of consecutive incremental means, along with a few useful variations.
The pieces are now all in place to derive equation 3.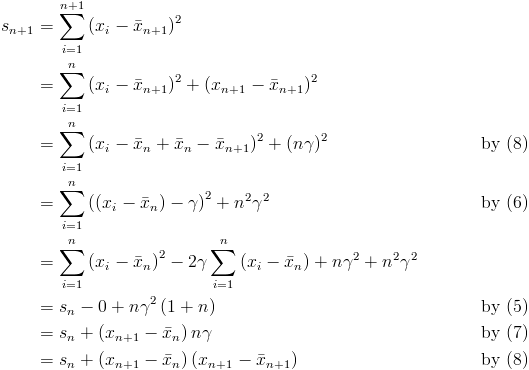
Friday, March 12, 2010
Embeding LaTeX in Blogger
The goal is to include mathematical equations in blog posts. My plan was to create images from the output of MacTeX. Apart from being painfully slow to crop and upload with multiple distinct equations, the LaTeX source would not be contained in the post.
Embedding LaTeX in HTML led me to jsLaTeX. Option 4 from Solutions for JavaScript Hosting in Blogger solved the Blogger hosting issue. After some CSS shenanigans we have Bayes rule right here, right now.
It is easier to write simple equations in the CodeCogs online equation editor first as Blogger preview doesn't seem to execute the JavaScript to render them.
Edit 23/03/2010: No longer using jsLaTeX, see Embedding LaTeX in Blogger take 2.
Friday, February 19, 2010
F# examples talk at BFG
Earlier this week I gave a short talk at the Brisbane Functional Group on F#. The idea was to give an introductory feel for the language by way of some simple examples. The talk was intended to be short so I assumed knowledge of previously discussed idioms such as tuples and curried type signatures.
I took the examples (with permission :-) from the environmental sensing project I work on at MQUTeR. This post is intended as a reference for those who attended rather than a self-contained introduction to F#.
- The
uncurryfunction was first up.let uncurry f (x,y) = f x y
We talked about the syntax of function definition, tuples and type inference in Visual Studio. We inserted the function into F# Interactive (the REPL available in Visual Studio) by highlighting it and pressingALT-Enter. The F# Interactive transcript went something like:val uncurry : ('a -> 'b -> 'c) -> 'a * 'b -> 'cThis lead to a discussion on operators and infix/prefix notation. The post F# Option orElse getOrElse functions should cover that.
> 1 + 2;;
val it : int = 3
> uncurry (+) (1,2);;
val it : int = 3
> (+) 1 2;;
val it : int = 3 - Next was the
|>operator, which has type signature'a -> ('a -> 'b) -> 'b.// Haskell catMaybes
We briefly compared
let catOptions xs = Seq.filter Option.isSome xs |> Seq.map Option.get
let euclidianDist (x1, y1) (x2, y2) = (x1 - x2) ** 2.0 + (y1 - y2) ** 2.0 |> sqrt
let spt' t a =
let m = Math.Matrix.ofArray2D a
allPeaks t m |> removeSmall |> dilate t m |> Math.Matrix.toArray2D
// type signatures
// allPeaks : float -> matrix -> matrix
// removeSmall : matrix -> matrix
// dilate : float -> matrix -> matrix -> matrix
// spt' : float -> float [,] -> float [,]|>with the Haskell$function, which has the type signature(a -> b) -> a -> b. - A quick look at type annotations, pattern matching and Haskell like guards. The example is an implementation of the MATLAB smooth function, which calculates a moving average. We didn't dwell on the entire function, just the relevant parts.
(*
yy = smooth(y,span) sets the span of the moving average to span. span must be odd.
If span = 5 then the first few elements of yy are given by:
yy(1) = y(1)
yy(2) = (y(1) + y(2) + y(3))/3
yy(3) = (y(1) + y(2) + y(3) + y(4) + y(5))/5
yy(4) = (y(2) + y(3) + y(4) + y(5) + y(6))/5
...
*)
let smooth s (a:float []) =
let n = (s - 1) / 2
let f i _ =
let (b, l) = match i with
| _ when i < n -> (0, i*2+1)
| _ when i + n < a.GetLength(0) -> (i-n, s)
| _ -> (i-(a.GetLength(0)-1-i), (a.GetLength(0)-1-i)*2+1)
Array.sum (Array.sub a b l) / (float l) // TODO try Array.average here
Array.mapi f a - Records are a common kind of data type. The labels are not automatically available as functions like they are in Haskell.
type 'a Rectangle = {Left:'a; Top:'a; Right:'a; Bottom:'a; Width:'a; Height:'a;}The F# overload-o-phone covers our discussion on arithmetic operators. The
let inline cornersToRect l r t b = {Left=l; Top=t; Right=r; Bottom=b; Width=r-l; Height=t-b;}
let inline lengthsToRect l t w h = {Left=l; Top=t; Right=l+w-1; Bottom=t+h-1; Width=w; Height=h;}
let fcornersToRect (l:float) r t b = cornersToRect l r t b // for C#
let left r = r.Left
let right r = r.Right
let top r = r.Top
let bottom r = r.Bottom
let bottomLeft r = (r.Left, r.Bottom)
let width r = r.Width
let height r = r.Height
let inline area r = r.Width * r.Heightinlinekeyword is mentioned in the comments. - Finally we looked at available API documentation. I find that I generally skim API documentation by first looking at function type signatures. The F# PowerPack is a useful library developed by the F# team and the format of the documentation supports my approach.
The F# API documentation was previously in this format. It has now been moved to MSDN and the list of function type signatures is not presented for each module, rendering it almost useless.
Thanks to everyone that participated in the discussion and I hope the talk was interesting.
Friday, February 12, 2010
QOTD
The role of the proof for mathematics is similar to that for orthography or even calligraphy for poetry. A person, who had not mastered the art of the proofs in high school, is as a rule unable to distinguish correct reasoning from that which is misleading. Such people can be easily manipulated by the irresponsible politicians.
-- V.I. Arnold
From: The antiscientifical revolution and mathematics
Thursday, February 4, 2010
Pair Programming again
I saw a local bank advertising a position to promote so called "sustainable software development" practices. These included Pair Programming, TDD, BDD and 100% code coverage.
I have written about Pair Programming before, but it needs re-iterating.
- The value of pair programming is not constant - it is a function of the problem, people and technologies at hand.
- If the problem at hand is not new or not complex the value is often significantly reduced.
- On common information systems / web projects (such as at this company) the problem at hand is often neither new nor complex.
- Therefore, if there is a project rule stating that all production code is to be paired on, the business value of the project will immediately be sub-optimal.
Anecdotally, with skilled developers of reasonable talent and discipline, the pair programming time on these types of projects doesn't need to be above 50%.
Monday, January 11, 2010

Tuesday, January 5, 2010
Home internet protection
We have a few macs at home and the kids are all in primary school. As they grow up they need to learn about computing and utilise the benefits of the internet. There is also the dark side that comes with internet access. I will continue to educate them about that, but at this early stage they also need protection and as they mature, I can reduce that.
OpenDNS
Content filtering requires registering our public IP address with OpenDNS. Our WAN router IP is dynamic and so I would need to update OpenDNS whenever we are assigned a different IP by our ISP. They have a windows and mac client to do this, but it should really be done on the router. My router doesn't support it, so OpenDNS is not suitable.
Mac parental controls
Apple has built in an option to try and restrict access to "adult" content automatically. I was pleasantly surprised to find that this worked with both Firefox and Safari.
I would have preferred a centralised option such as OpenDNS so I didn't have to configure each machine. However, I will try the inbuilt mac parental controls to start with and will investigateDansGuardian should it fail.
