Given a list of n numbers 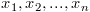 , the variance is defined as
, the variance is defined as
where  is the arithmetic mean.
is the arithmetic mean.
Expression 1 stated in words is the average squared difference of each data point from the mean. Implemented as an algorithm, this requires two passes over the data set. The first to calculate the mean and the second to sum the squared differences.
Let's derive the more commonly used expression for variance.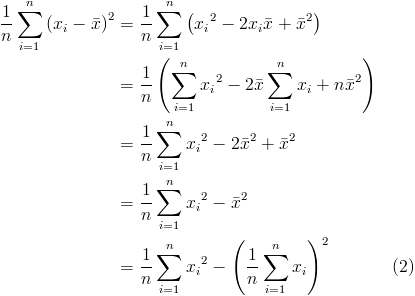
This only requires a single pass over the data set, computing the incremental sum of the values and the incremental sum of their squares. However, if the terms in the subtraction are large and close enough, catastrophic cancellation can occur. Essentially the precision of the floating point representation is exceeded, yielding unacceptable results. See Algorithms for calculating variance and Theoretical explanation for numerical results for examples (they are calculating the sample variance which is slightly different). More detailed information on catastrophic cancellation can be found in What Every Computer Scientist Should Know About Floating Point Arithmetic (1991).
A more numerically stable (but computationally expensive) single pass algorithm was published by Knuth in The Art of Computer Programming, volume 2. Define 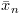 and
and  as the mean and sum of squared differences of the the first n values respectively.
as the mean and sum of squared differences of the the first n values respectively.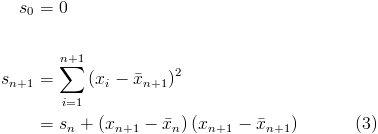
For m > 0 values, the variance is then  .
.
Derivation of Equation 3
This is really just a more verbose version of one-pass algorithm to compute sample variance. First up is the running mean.
If you think of the mean visually i.e. a horizontal line through the data on a scatter plot, then it is intuitive that the sum of the distances between each point and the mean is zero.
Now define  as the difference of consecutive incremental means, along with a few useful variations.
as the difference of consecutive incremental means, along with a few useful variations.
The pieces are now all in place to derive equation 3.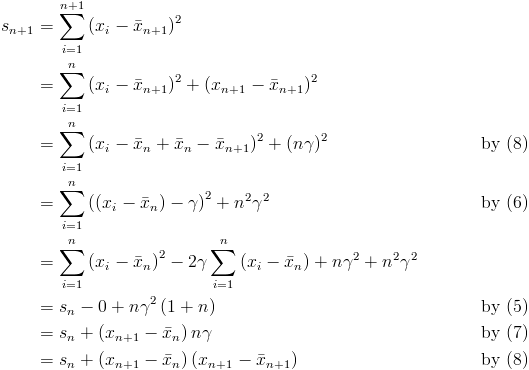
Sunday, March 21, 2010
Computing variance
Subscribe to:
Post Comments (Atom)

No comments:
Post a Comment