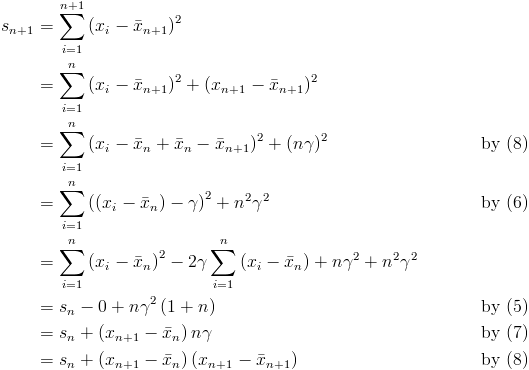After further consideration on Embedding LaTeX in Blogger I have the following concerns in using jsLaTeX.
- LaTeX images not rendered in RSS readers
- Stability of all the components over (a long) time
jsMath improves on point 2, but looks way too hard to host on Blogger. So I am falling back to using images generated by the CodeCogs online equation editor hosted on Picasa, which is where Blogger uploads images. I put the LaTeX source in the
img alt attribute.Blogger resizing images
After adding a few equations through the standard Blogger mechanism, I noticed that they weren't as clear when previewing. The following two equations are the same image hosted on Picasa, but embedded with different src urls.
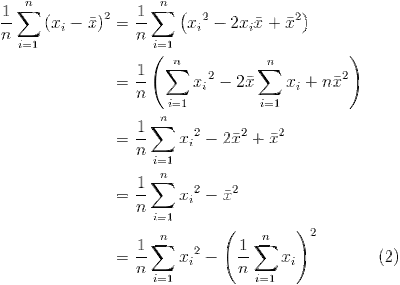
This is using the Blogger generated url in the image tag and has size 400 x 285 pixels.
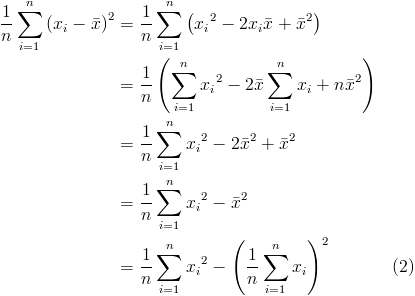
This is using the Picasa generated url and has the original size of 415 x 296 pixels.
Notice how the first image is both smaller and blurry. It seems that Blogger is automatically resizing it. Unfortunately this means a little more work for each equation as it requires generating the link in Picasa and replacing the Blogger generated image tag.
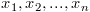 , the
, the 
 is the
is the 
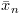 and
and  as the mean and sum of squared differences of the the first n values respectively.
as the mean and sum of squared differences of the the first n values respectively.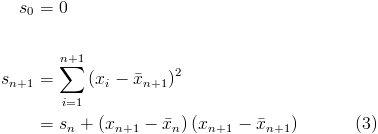
 .
.

 as the difference of consecutive incremental means, along with a few useful variations.
as the difference of consecutive incremental means, along with a few useful variations.